I am happy to announce that starting today we will start working on a project funded by the Prototype Fund. The goal of this project is to make KUserFeedback store all the data it collects only on users’ devices. KDE will be able to perform distributed analysis of this data while maintaining user privacy.
This will be very helpful for KDE, as they will be able to get answers to questions like who their users are and how they use KDE products, and thus e.g. optimize the user experience.
For KDE users, it will improve the privacy situation. They can contribute with their personal data to the project without compromising their privacy.
For privact, this project serves as a first proof of concept to demonstrate the concept of distributed data analysis.
We will keep you informed about the progress in this thread. The project itself is hosted on gitlab.
We’ve decided to do ~weekly reports here on what we’ve been up to. Might be on a bit of a detailed level, but that’s the cost of transparency in my experience
I’ll make the start for this week, since it was the first week of the project. For some background on how it works:
We have six months (so from March 1st until end of August) to get a working prototype / proof of concept for this whole thing.
During this time, @RSto and I will both work ~8 hours per week on this, with @bjoern supporting us with direction, UX and most things unrelated to code, I suppose.
Our general approach is to have something working at all times. At first this will only very vaguely resemble the vision we have for all this, but it’s something.
As for my first report:
I’m gonna start with something I didn’t do: I wanted to make sure we have the plan and roadmap documented in more detail than what we currently have in the project wiki. Didn’t get around to that just yet
We set up the repository with an initial version of the client and server. I personally mostly worked on the client, the thing that’s gonna store personal data. It’s just a few lines of code so far, but it’s gonna reach out to the server to get a list of surveys (i.e. data the server is interested in), and then just prints that. So mostly project setup / hello world kind of stuff so far.
But hey, still exciting to start moving this along! I think in the next 1-2 weeks (i.e. 1-2 days for me and @RSto) we’ll have a more meaningful initial version working. And then we can start to dig into the juicy bits.
While client and server are concepts, which don’t match perfectly for what we’re developing, this naming is good enough for now.
I focused on the server this week and we got to a point where we enabled communication between server and client. Also building a basic interface to create surveys in a rudimentary way. Nothing more to add to Felix report in that regard.
Looking forward to finishing the setup/ hello world part as @fhd called it and starting with a central piece. The federation.
To give the reports more structure we decided to add three categories done, doing and challenges and since @fhd and I are working together quite closely and to avoid redundancy, we also decided to take turns doing the update.
Done:
We added a first naive storage to the client to store arbitrary data like timestamps for now.
We added the counterparts for the server objects like surveys, queries (basically a question as part of a survey) and responses to these as well as tests for all of those.
@fhd took it on himself and blessed us with some quality of life changes to the building process of the client.
Doing:
Finish the communication flow of client asking for surveys, receiving them and answering to those it is interested in (no federation yet).
Adding commissioners to the surveys on the client and as part of the communication (only answering to KDE surveys)
Separate the client into daemon and UI
Challenges:
For the federated data aggregation we will need to make a concept on how this can be achieved. We will do some research on existing solutions and implement a first naive one ourselves.
Quick reminder that you can get a more detailed view on what we’re up to by looking at the repository and the issues, since it’s all public.
Done:
We now have the first round trip working: Clients pull surveys from server, fill out a response with the local data (for the time being only timestamps), and send it back to the server, which stores the results. For now, the clients will respond to all surveys from the commissioner “KDE”, and ignore all others.
The client now runs as a daemon (i.e. consistently in the background) rather than just once.
We’ve got an initial UI (even though all it does is say hello world, but that’s how things start )
Doing:
Log all responses a client sends to a server and show them in the UI. For this we will need some initial inter process communication between the client’s daemon and UI. That’ll give the user some overview over what data has been sent to whom.
A whole lot of research. We want to get on top of the current state of Solid, we want to investigate Flower, SecAgg, and a bunch of other relevant projects. As long as it’s open source and feasible, we want to “steal” what we can And also think about how we can collaborate with these projects that have similar goals to us.
Challenges:
We’re still not entirely sure how the federation mechanism is going to work, so we’ll deep dive into research soon and try some stuff out. If none of that turns out to be promising enough, we do have a pretty good idea for an initial mechanism that we could implement ourselves, but we hope we can save a bit of time by basing it on existing tech.
Not a particularly unexpected challenge, but since it’s the local Easter vacation starting next week, all three of us are on vacation for one week in this time frame. They don’t overlap, so we’ll make some progress each week, but a bit less probably. From the second week of April on, we’re back in full force.
Last week I was out, this week it’s Richard. But there’s been a little progress:
Done:
Various code quality improvements for the client, most notably the addition of clang-tidy, which does some static analysis to help us avoid introducing code quality issues (or memory issues even).
Automated building, linting and testing in GitLab CI for both client and server. This’ll help us keep everything working, and also make it easier for us to find out which particular commit broke the build or a test.
A first crude version of the client-side UI showing all the survey responses the daemon sent to the server so far. Still needs to be displayed in a nicer way, and UI/daemon should communicate via proper IPC instead of accessing the same database, but it’s a first step.
Doing:
Improve how the client-side UI retrieves and shows survey responses.
Get a demo with federated aggregation using flower working.
Challenges:
Figuring out how to best do federated data aggregation is going to need a whole lot more research and experimentation. We’re trying to use an existing approach, and there’s a few out there, but they’re all pretty fresh and thus rough around the edges and non-trivial to integrate/implement.
Skipped last week as we were experimenting and had no real accomplishments at that point.
Done:
Conceptualising about our federated standard deviation calculation protocol. We made a wiki page on how we imagine it here.
Implement the conceptualised protocol as an experiment with flower and SecAgg. This was more tricky than I’d have hoped, like it often is with research code rather than production ready software. But it works and could be the basis of our client/ server aggregation communication in the future.
Doing:
Try other analyses in the experiment project with flower and SecAgg.
Improve the client-side UI to be less crude in showing the answered surveys.
Implement the flower/ SecAgg experiments in the codebase.
Challenges:
While the experiments yielded a result, it is still unclear how well it works with the actual C++ client (we got it working with a dummy python client).
This week was more thinking and writing than programming, but we had to get a bit more clear on our approach, and we had to document some of the things we’ve been investigating / thinking about.
Done:
We’ve determined and documented our high-level architecture, see the Architecture wiki page. In a nut shell, we aim to combine local analysis with both federated aggregation and secure aggregation (using the SecAgg protocol).
We’ve reviewed the code of KUserFeedback, analysed the data model and documented the relevant parts, see the KUserFeedback wiki page
Doing:
Improve the client UI to show survey responses (we’ve been dragging this one along for a few weeks, it’s just not that time pressing, but we’ll get it done one of these days)
Implement an initial local analysis (without any “transformation” at this point) in both client and server
Add a way for the client to receive data from KUserFeedback (and potentially other sources), presumably via D-BUS
Challenges:
We will probably need to decide what to do first: Federated Aggregation or Secure Aggregation, there’s a good chance we won’t be able to finish both in the scope of this project. We’re currently leaning towards Federated Aggregation. We have 1-2 weeks to make this decision, since we’re doing the (arguably more pressing) local analysis part first.
As documented in the wiki, in order to combine Federated Aggregation and Secure Aggregation, we will need an implementation of the SecAgg server and client which we can use in both our server and client. The best thing we found so far is the Python implementation from Flower, but even that one is a bit work in progress. They have a client implementation in C++, but for proper portability we’d need a server implementation in C++ (or C, or even Rust) as well. For the scope of this project, we can probably get away with using their Python server/client implementation on our client though, sacrificing portability temporarily.
No progress worth mentioning last week - both @RSto and I were both occupied with other things.
This week, however, is looking pretty solid!
Done:
Improved the client UI to show survey responses (finally!).
Added a D-Bus service to the client, which other applications can use to submit data (up until this point, we’ve been working with generated fake data).
Doing:
Implement analysis based on the cohort mechanism we came up with.
Challenges:
While we got to one of the juicy parts now (actually sending meaningful non-raw data to the server), changing to that from raw data submission required quite a few more changes to client and server than we anticipated, so it’s taking longer than we thought.
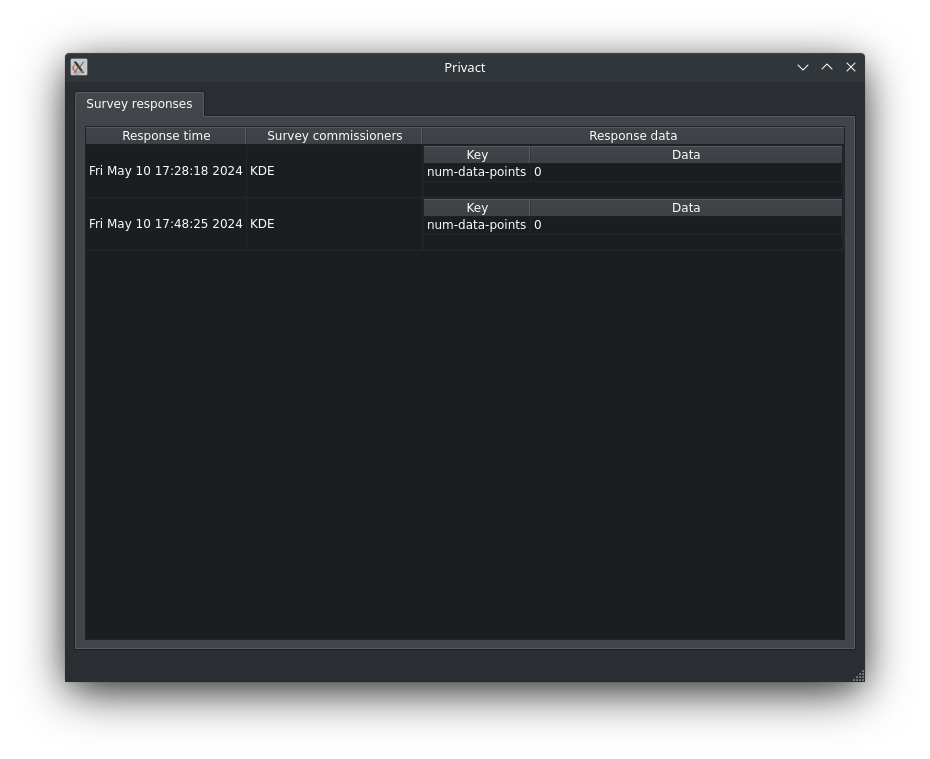
While it’s not much, it’s the first time there’s really anything to see, so here’s what the survey response UI (where users can see what data they submitted to whom) looks like right now (hard to believe I guess, but this is a lot better than what we had before, but certainly not final):
Tests for the server side of the federated aggregation protocol
Federated aggregation protocol client side (signup mechanism only)
Doing:
Implement rest of the federated aggregation protocol on the client side
Implement DeKUF integration in KUserFeedback
Challenges:
Creating integration tests for the new federated aggregation protocol is tricky (we need to spawn several clients etc), and something we pushed to a later time.
We noticed that we probably can’t use a Secure Aggregation implementation without any modifications, as we had initially hoped.
We haven’t been so good at keeping up with this thread for a multitude of reasons, but since the DeKUF project is about to conclude next week, here’s another update:
Done:
Changed client logic to be synchronous and brought some unit tests back we couldn’t get to work with the previous asynchronous logic.
Added Pallier encryption for raw data sent to the delegate: This allows the delegate to aggregate the data from other clients without access to their raw data.
Extract the data model of the queried data from the surveys and queries - resulting in a more explicitly configured data model on the server.
Doing:
Improve test setup to make it easier to demo the protocol with multiple clients.
Create a fork of KUserFeedback that will sent data directly to the DeKUF client, closing the loop on what we set out to demonstrate with this whole project.
Add end to end encryption for messages sent between clients (via the server).
Update our wiki and generally improve the generic documentation a bit more to be in line with what we actually built in the end, and how it contrasts with similar projects.
Challenges:
While (1)-(3) are technically more challenging than they sound like, they’re doable. Our big challenge this close to Demo Day is that we need to make sure we get the right things done, considering we won’t have time to finish everything on our list. As the list above reflects, our priority is to be able to demo this, after that we want our prototypical implementation to cover everything a production implementation of the protocol we came up with would need, and lastly we want to get the project into a state where it’s easy - or at least possible - to continue this work with a larger group, e.g. the KDE community.
Outlook:
I think we did some surprisingly good work here in the end. Naturally it was trickier than we thought, but I think we honed in on a pretty good protocol, with some ideas in it we didn’t have when we first started this. While it’s technically still a prototype, we did built something that works, implements the crucial bits of the protocol we came up with (at least it should next week :P), and most importantly, we went from vague ideas on what to do in Privact to a pretty clear first idea. Sometimes the solution only takes shape when you start building it, and we certainly had that effect here.
Next Tuesday is Demo Day, where we’ll explain and demonstrate the prototype and the project to the crowd from Prototype Fund, which includes visitors unaffiliated with Prototype Fund and the projects, so there might be some interesting things coming out of it. The week after, we’re going to run a workshop at Akademy, the annual KDE conference, where we hope we can create some traction for the KDE project to adopt this approach; helping to develop it further, and shipping it to a quite non-trivial amount of end users.
So I’d say it was a bumpy ride, but it looks like a success to me. At this point I want to thank @RSto for his great work and good collaboration on this, and most of all @bjoern for making it all possible out of thin air.
Moin@fhd and @RSto .
As far as I’m concerned, you both communicated well and sufficiently in the thread…and let Björn digest the rest
I think what you describe is very good news. What you have achieved and accomplished in such a short time and with the resources available to you is really great.
I (and I’m sure we all) would like to take this opportunity to express our praise and appreciation.
A truly great achievement !!!
For the ‘Demo Day’ and the ‘Workshop at the Academy’ I (and again I’m sure we all ) are keeping our fingers crossed for you and I’m sure you’ll rock the house.
And last but not least, a big thank you from me to @bjoern for what he has achieved so far and I am already looking forward to what the future will bring for our project.